

Python制作一个简单的智能聊天机器人的实现
温馨提示:这篇文章已超过829天没有更新,请注意相关的内容是否还可用!
最近两天需要做一个python的小程序, 就是实现人与智能机器人(智能对话接口)的对话功能, 目前刚刚测试了一下可以实现, 就是能够实现个人与机器的智能对话(语音交流)。
总体的思路
大家可以设想一下, 如果要实现人与机器的智能对话, 肯定要有以下几个步骤:
计算机接收用户的语音输入
将用户输入的语音输入转化为文本信息
调用智能对话接口, 发送请求文本信息, 获取接口返回的智能回答文本信息
将回答文本信息转化为语音格式输出
这里可以安装很多现成的库函数, 辅助我们系统的实现。
需要准备的环境
以下是需要安装的一些python依赖包
pip install pyaudio 安装pyaudio依赖包, 用于录音、生成wav文件
pip install baidu-aip 安装百度AI的sdk, 调用语音技术接口将音频识别为文本数据返回
pip install pyttsx3 安装pyttsx3依赖包, 将文本信息以音频的格式播放出来
接下来我会逐步实现以上每个功能, 最后再组合起来。
接收用户的语音输入, 并将其存为音频文件
import time
import wave
from pyaudio import PyAudio, paInt16
framerate = 16000 # 采样率
num_samples = 2000 # 采样点
channels = 1 # 声道
sampwidth = 2 # 采样宽度2bytes
FILEPATH = '../voices/myvoices.wav' #该文件目录要存在
#用于接收用户的语音输入, 并生成wav音频文件(wav、pcm、mp3的区别可详情百度)
class Speak():
#将音频数据保存到wav文件之中
def save_wave_file(self, filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
# 进行语音录制工作
def my_record(self):
pa = PyAudio()
# 打开一个新的音频stream
stream = pa.open(format=paInt16, channels=channels,
rate=framerate, input=True, frames_per_buffer=num_samples)
my_buf = [] # 存放录音数据
t = time.time()
print('正在讲话...')
while time.time() < t + 5: # 设置录音时间(秒)
# 循环read,每次read 2000frames
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print('讲话结束')
self.save_wave_file(FILEPATH, my_buf) #保存下录音数据
stream.close()调用百度AI接口, 识别音频文件并以文本信息返回
之前使用过好几次百度AI的接口,我的毕业设计<在线课堂学生异常行为与分析>也是使用到了百度的智能平台, 个人调试的话有很多免费产品,总体来说百度在人工智能领域做得还是相当不错的。
在调用百度AI接口之前, 需要首先进入百度AI开放平台,搜索语音识别
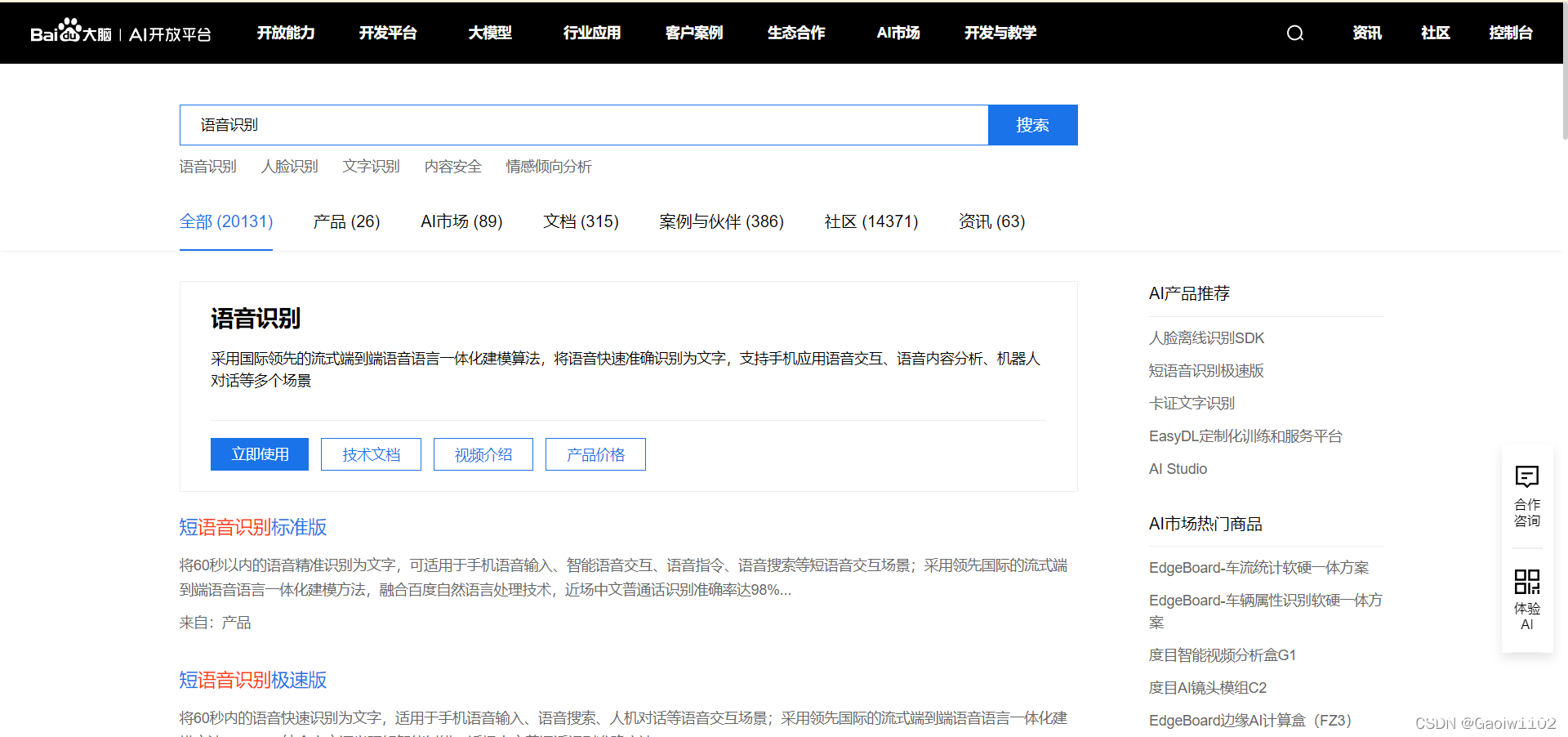
点击立即使用, 没有账号的话可以先创建一个账号, 然后领取免费的资源使用
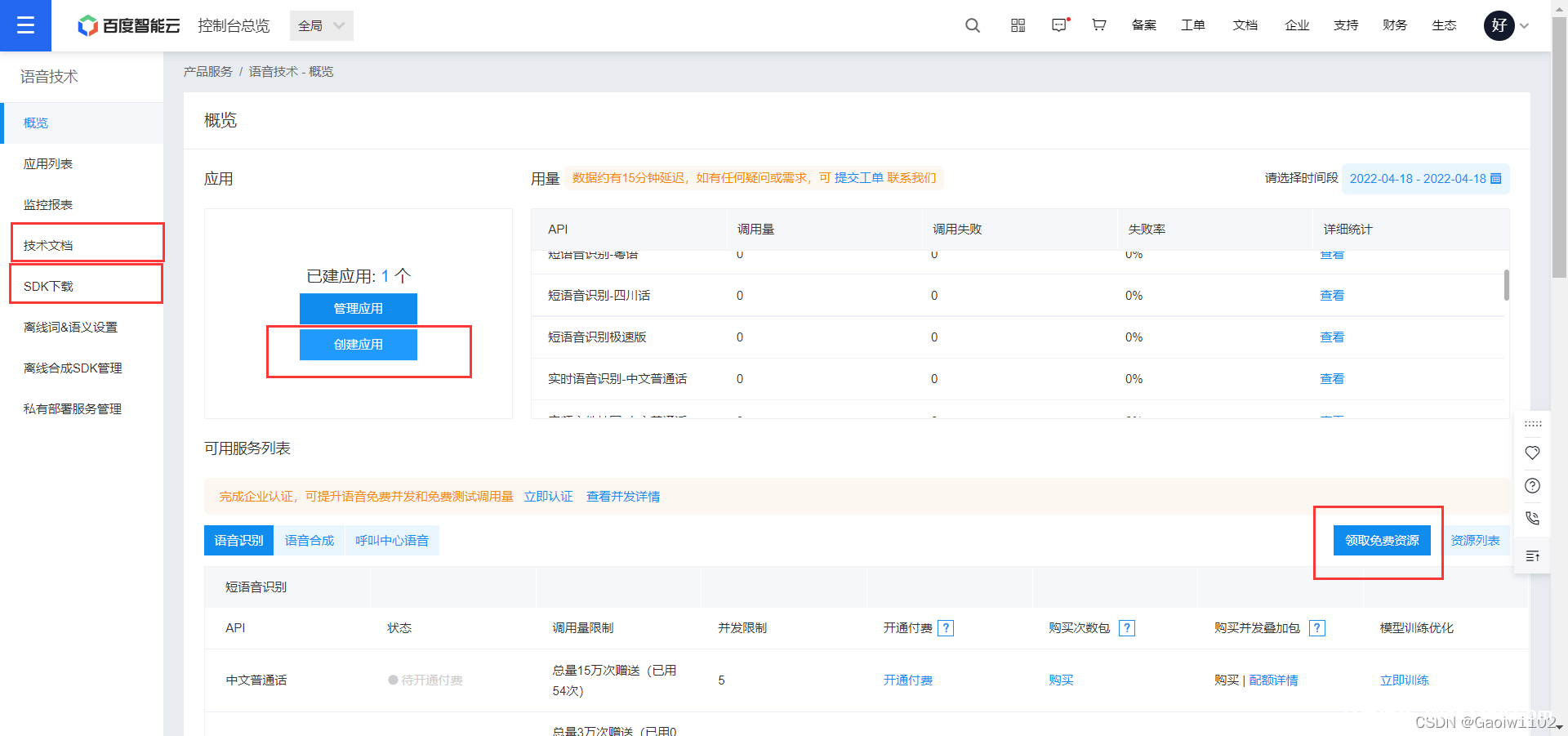
我之前已经创建1个了, 假设再次点击创建
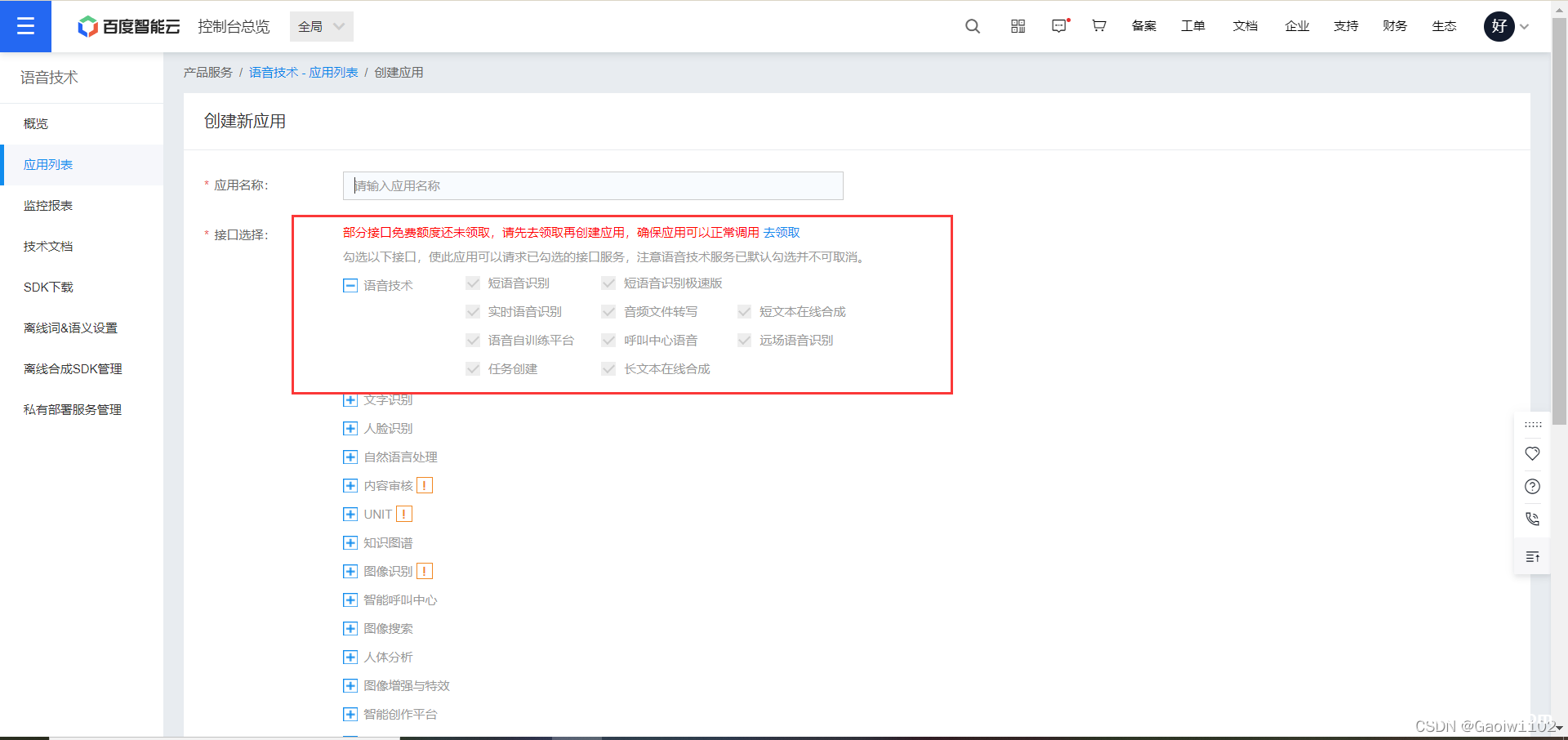
系统会自动勾选上语音识别接口, 直接创建应用即可,之后会有 AppID、 API Key、Secret Key,之后调用百度接口直接调用即可,

可以查看接口文档,进行具体的接口操作
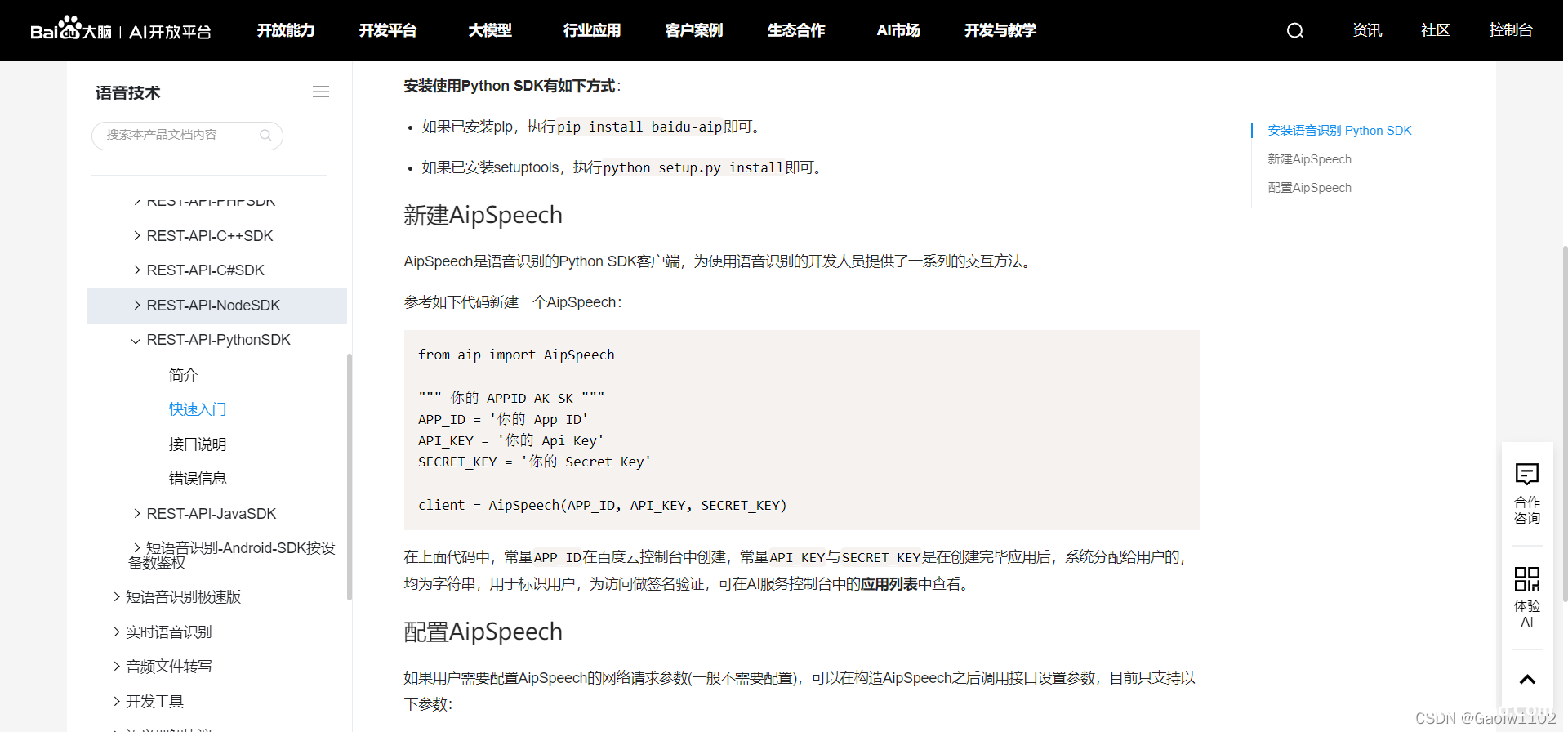
前奏准备好, 便可以直接调用接口进行语音识别
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '25990397'
API_KEY = 'iS91n0uEOujkMIlsOTLxiVOc'
SECRET_KEY = '' #此处填写自己的密钥
"""调用接口, 调用BaiDu AI 接口进行录音、语音识别"""
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
class ReadWav():
# 读取文件
def get_file_content(self, filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def predict(self):
# 调用百度AI的接口, 识别本地文件
return client.asr(self.get_file_content('../voices/myvoices.wav'), 'wav', 16000, {
'dev_pid': 1537,
})
readWav = ReadWav() #实例化方法
print(readWav.predict()) #调用识别方法, 并输出执行结果(音频文件存的录音是: 你叫什么名字呀?)
{'corpus_no': '7087884083428433929', 'err_msg': 'success.', 'err_no': 0, 'result': ['你叫什么名字呀?'], 'sn': '255158586831650276613'}请求智能机器人, 发送文本信息, 返回智能聊天内容
之前我们老师推荐我使用图灵机器人的智能聊天, 后来发现认证一直无法通过, 且需要付费
之后参考知乎大佬的回答
发现了一个免费、无需注册、只需要发送get请求就可实现聊天的青云客智能机器人,直接调用接口即可
代码如下:
def talkWithRobot(msg):
url = 'http://api.qingyunke.com/api.php?key=free&appid=0&msg={}'.format(urllib.parse.quote(msg))
html = requests.get(url)
return html.json()["content"]
print(talkWithRobot("你好呀!"))输出
哟~ 都好都好
将回答信息转化为语音文件并输出
此处需要导入pyttsx3包,具体代码如下
import pyttsx3
class RobotSay():
def __init__(self):
# 初始化语音
self.engine = pyttsx3.init() # 初始化语音库
# 设置语速
self.rate = self.engine.getProperty('rate')
self.engine.setProperty('rate', self.rate - 50)
def say(self, msg):
# 输出语音
self.engine.say(msg) # 合成语音
self.engine.runAndWait()
robotSay = RobotSay()
robotSay.say("你好呀") #会讲出 ~你好呀(女声)组合成为自动聊天机器人(它很硬气)
代码如下
def talkWithRobot(msg):
url = 'http://api.qingyunke.com/api.php?key=free&appid=0&msg={}'.format(urllib.parse.quote(msg))
html = requests.get(url)
return html.json()["content"]
robotSay = RobotSay()
speak = Speak()
readTalk = ReadWav()
while True:
speak.my_record() #录音
text = readTalk.predict()['result'][0] #调用百度AI接口, 将录音转化为文本信息
print("本人说:", text) #输出文本信息
response_dialogue = talkWithRobot(text) #调用青云客机器人回答文本信息并返回
print("青云客说:", response_dialogue) #输出回答文本信息
robotSay.say(response_dialogue) #播放回答信息运行结果(发现它很硬气)
""" 正在讲话... 讲话结束... 本人说: 你好呀。 青云客说: 哟~ 都好都好 正在讲话... 讲话结束... 本人说: 你叫什么名字呀? 青云客说: 我是小美人菲菲呀~ 正在讲话... 讲话结束... 本人说: 哇,那你多美呀。 青云客说: 你似有問題多啲囉! 正在讲话... 讲话结束... 本人说: 我好看吗? 青云客说: 你真是个地道的美人啊。就是说你只有在地道里才算美人,因为地道里没灯 正在讲话... 讲话结束... 本人说: 你可真是个小可爱呀。 青云客说: 呀,你怎么知道。。。我就是啊。。 正在讲话... 讲话结束... 本人说: 不和你说了。 青云客说: 不说拉倒 """
后续
现在就是功能的一个简单组合, 之后会做出来一个GUI界面,多增加点功能,分享给大家!



